Some things I learned implementing Data Fetching for Universal Web Apps
José M. Pérez / July 16, 2016
7 min read • 463 views
Javascript is not just a language for the browser. Node.JS is becoming popular as a platform to run JS on the server. We are learning how to build modular websites where business logic and state are not coupled with the markup. And finally we are getting the tools to build universal web apps. But what are universal apps, and why should we care about data fetching?
Universal/Isomorphic apps
The community hasn’t decided on what to call them yet, but for the sake of consistency I’ll be referring to them as universal web apps. These projects have 2 main features:
- The server runs JS
- Most of the code of the project is shared between browser and server.
For a long time we tangled business logic with markup. We would generate some HTML in the server and JS would run in the client to make AJAX requests and changes in the DOM.
This worked for most websites, but today lots of projects start as a SPA. Their state is managed in a single place and the server just provides the initial page and a set of endpoints that return data to the view. But this approach has caused long page load times and bad SEO forced rethinking the web.
The best way to provide fast-loading pages is to server-side render them. Though service workers might help eventually, the initial request needs to reach the server. To compose the page, the server needs to identify the user, fetch some data and generate the markup through some template system. After the initial load, JS comes in and replaces full page loads with some data fetching and markup composition.
Here we can see that some code will be duplicated, especially in SPAs. A way to improve this is by running JS in the server and trying to write code that is decoupled from the DOM. Server-side rendering can be seen these days as an enhancement for SPAs.
Data fetching in universal apps
In universal apps, most of the code can be shared between browser and server. One of the pieces that differs is data fetching. Node.JS has its own way to make requests, and neither XMLHttpRequest nor fetch is supported.
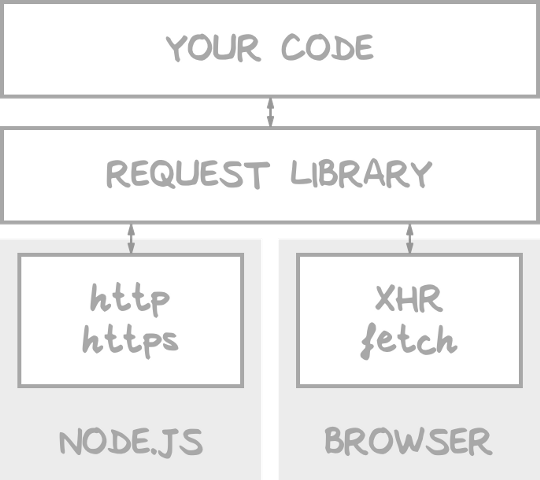
Universal request libraries abstract your code from how a request is made.
There exists many libraries that will perform the async requests using the mechanism available in the platform running the code. Some of them try to polyfill fetch in Node, others polyfill http in the browser. In our code we require/import them, and then the code is included in the bundle served to the browser using browserify or webpack.
Choosing a universal request package
Regardless of which request library one you choose, be aware of how they contribute to the bundle size. Ideally, these libraries should represent a rather small chunk of the bundle, but I have been doing some tests and the results are pretty interesting.
I have used browserify to create a bundle just requiring each of there libraries separately, and then uglified the output. The size shown is minified, not gzipped:
- iso-http 0.0.5: 4kB
- isomorphic-fetch 2.2.1: 9kB
- superagent 2.0.0: 9kB
- axios 0.13.0: 20kB
- isomorphic-request 1.0.0: 240kB
- node-fetch 1.5.3: 489kB
Note that these packages might not have the same features, and I haven’t tried most of them myself. In some cases it might be worth creating your custom request library accesses the endpoints you are using. But all in all these libraries should generate code that wraps XMLHttpRequest and its response.
Notice the big difference in size between them, all the way from 4kB to 489kB. How can that be? For that we need to understand what is going on when our code is bundled.
Bundling of Node's APIs
Something I learnt while creating those bundles is that it is very useful to double check the generated code. If the required code includes some feature only available in Node, the bundler will add the JS code for it in the output bundle.
An example is Buffer, which I was using in a wrapper for the Spotify Web API. Since Buffer is not supported in the browser environment, which accounts to 44kB of JS (minified).
Same thing can happen with these request libraries when they include code that is supposed to be only run in Node.JS and not on the browser.
The browser field
When you are bundling some JS code that is going to be run only on the server, do not include it in the bundle that is going to be run on the browser. This applies both if you are writing a site and if you are writing a library that will be used by another project.
For this, use the browser field in the package.json file. It is used, amongst others, to define what file needs to be replaced by other when bundling. When using webpack, make sure target is not set or set to 'web'.
You can see an example in the superagent source code:
{
"name": "superagent",
...
"browser": {
"./lib/node/index.js": "./lib/client.js",
...
},
...
"main": "./lib/node/index.js",
...
}
or iso-http:
{
"name": "iso-http",
...
"main": "js/node/Http.js",
"browser": "js/browser/Http.js",
...
}
From the libraries I tested, 4 of them were using browser and 2 of them not. These 2 are precisely the ones that generate the largest bundle files.
Getting stats about a bundle
It is not straightforward to know what modules are contributing the most size to the output bundle. One way you can try is by creating an entry JS file that only includes the module you are interested in, which is what I did when comparing request libraries. But if you are using webpack, a better way is to use webpack-visualizer.
This tool generates a pie chart with all the required dependencies and makes it straightforward to find the culprit.
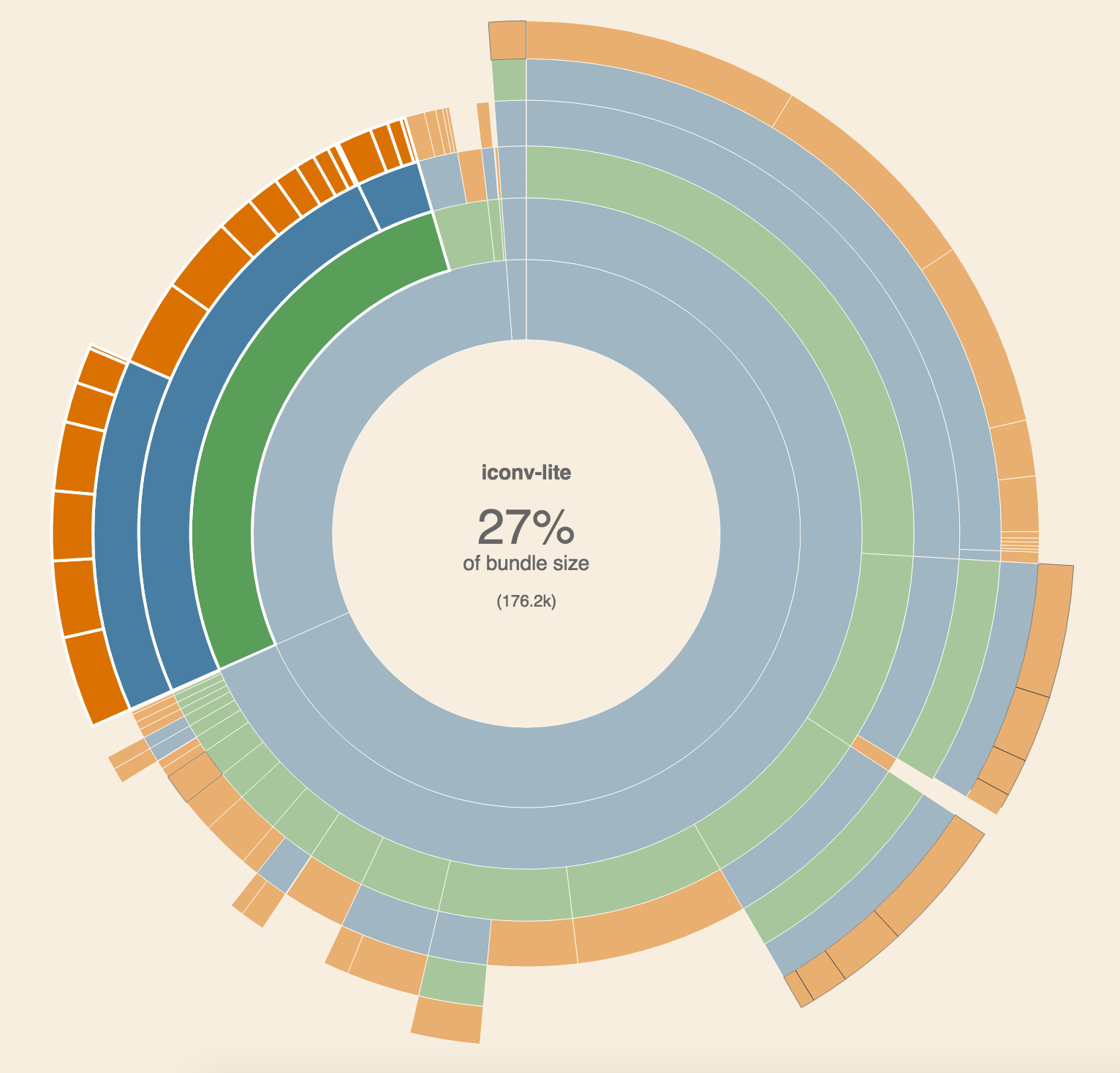
iconv-lite and pako are the main contributors to node-fetch bundle size.
One more thing: ES6 imports
A great way to reduce the footprint of a library is by exporting it in pieces. Thanks to ES6 and tree-shaking, one can import a subset of functions and symbols from a library, which can reduce largely the size of the output bundle.
This is really useful if you are implementing a wrapper for your API endpoints. It is convenient to support all the endpoints, but an app might only be interesting in using a few of those.
I have started experimenting with this building a new wrapper for the Spotify Web API that exposes each endpoint as an exported function, so that the unused endpoints are not part of the generated code.
Conclusion
Universal apps are great, and so is sharing lots of code between server and client. As important as a fast rendering time is the time it takes the browser to download, parse and execute the JS that provides the client-side functionality. Keep an eye on your imports, and prevent including code that is not intended to be run on the browser.