Fostering a Web Performance Culture
José M. Pérez / June 02, 2018
20 min read • 1,589 views
Web Performance is not only about understanding what makes a site fast. It's about creating awareness amongst both developers and non-developers. Performance is a feature and needs to be prioritized as such.

Performance is a topic that has interested me for a long time. I remember when I learned about dynamic programming, greedy or divide and conquer algorithms. There was something gratifying in taking a code that takes minutes to run and make it run in a handful seconds.
Moving over to web, the performance problems are different. Usually, they are not related with computational complexity, but about serving what's needed when needed in the best possible way. It might seem like a no-brainer, but it's more difficult than it seems.
Steve Souders was one of the first in reverse-engineering how browsers requested and waited for resources. What resources are blocking? Which ones can be delayed? What about the response headers? He put together a list of 14 rules for faster-loading web sites. If you have ever used YSlow, those are the rules the tool was using to flag performance issues.

Steve Souders' 14 Rules (source)
These days we have more and better tools to audit our performance. They can be run as a one-off or integrated in our development and deployment pipelines. Google's Lighthouse is one of them, which shows information about PWA, SEO and more.
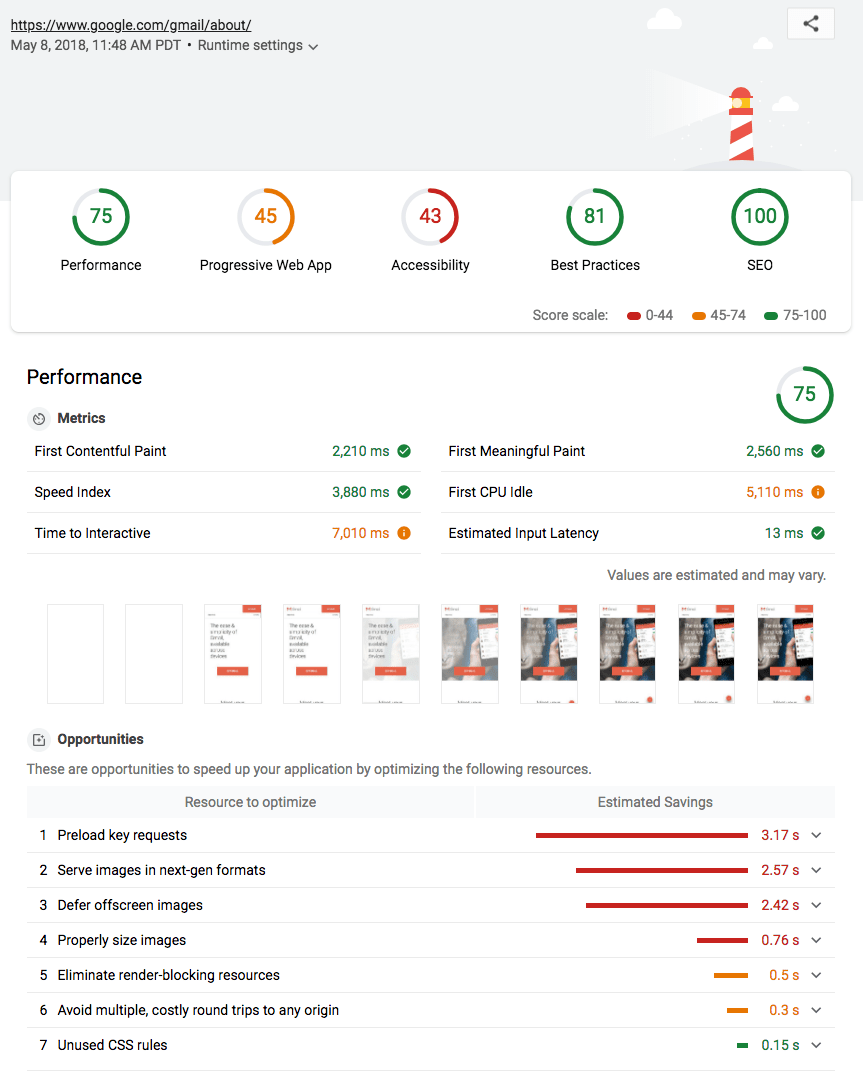
A screenshot of Lighthouse 3.0, presented in Google IO 2018 (source)
These tools make it easier to determine where we need to put emphasis to improve our sites. At the same time, they open a door to lots of concepts that might be overwhelming: PRPL, RAIL, Paint Timing API, TTI, HTTP/2, Speed Index, Priority Hints and more…
Why Performance doesn't get Prioritized
Web performance at organizations is a real challenge. We have better guides and tools than ever, yet very few companies get to spend time improving performance. You see, it's not that we don't know what causes long blank screens on our sites.
This is not a post explaining why web performance is important.
There are plenty of other resources that do a way better job, with real numbers from real projects. This is a post about culture and how it determines what is a priority in our companies. Only by understanding that can we prioritize performance as another feature of our projects.
If you are reading this you are likely a developer who knows about web and cares about performance. You can represent your team and company if I ask you about where you work and what you do. But most likely you are not representative for the rest of web developers in your team and company, unless you are working on your own. And this is fine. The same way you can't know everything about every discipline.
In your daily job you have lots of technical areas to care about. You will work hard on implementing features, collaborating with other teams (eg adding scripts for analytics, ads, retargeting, A/B test), setting up CI/CD, ensuring security, and making sure the project is usable and pleasant to the eye. And don't forget about covering your back with tests.
You might never have time to look beyond that. Time is finite while your backlog is ever increasing. There needs to be some prioritization.
The prioritization should be objective and based on measurable hypothesis. “We think that by implementing feature X, user retention will grow Y%”. In practice this setup is more difficult. Let's take a look at those topics we need to care about and think about who proposes them:
-
Implementing features: Normally a PO/PM determines what needs to be done next, according to a vision and mission for the team. The feature might come from stakeholders that have a dependency on us (eg adding a third-party script for tracking or A/B testing)
-
Setting up CI/CD: Although developers could come up with their own build and deployment pipelines, chances are that they are relying on some infrastructure provided by another team (eg an “infra” team)
-
Security: Hopefully there's a team or individual with deep knowledge about security that help us reviewing system designs, implementations, and informs us about reports or and security patches.
-
UI/UX: There is usually a designer and/or UX person that sets the look & feel and information architecture.
-
Testing: Well, we should write some tests, right?
When someone has the responsibility for a task to be done it will be more likely to be on the board. Most of them can be traced back to a certain role, but others like testing are something developers are supposed to do. Tests are up to the team, and so some parts will be better tested than others.
We agree that having automated tests is positive. Normally the team decides how well to cover and test the code, and it's important that all developers in a team know how to write tests. Similar to testing, performance is usually left to the developers to figure out. I find that it is easier to write tests for a piece of code and knowing the implications of broken code in production, than understanding all the moving boxes that can lead to a bad web performance.
6 steps to start a web performance culture
We have the tools to measure performance, though working on it will be up to the team. How can we reach awareness, think of performance as a feature, and have the support of the company?
I have collected a list of 6 ideas that will take you closer to establish a web performance culture.
1. Your dev environment is not your user's environment

Light Work, a picture by Émile Perron
I use a Macbook Pro to develop websites. I have an iPhone X as my phone, and my testing device. Also, the speed of my internet connection is humongous and I'm close to data centres located in Stockholm and London. When I finish my job for the day I take the subway, where I have an uninterrupted 4G connection. In fact, Stockholm was the first city in installing 4G back in 2009.
Except for exceptionally few cases, the users of your product don't have a similar environment. Not even close.
How can we prioritize performance if we don't perceive performance issues? It's like making something accessible without trying to use keyboard navigation, screen readers nor color contrast checkers. There is no way.
And this is not about to change. Western web developers enjoy using the latest laptops and gadgets. And the chain goes up to pretty much any person responsible for prioritizing tasks and project are your company. Not only that, but in some cases we may prioritize top devices because those are the ones used by the users that are most likely to pay for our product. As Bruce Lawson put it, we should be building the “world-wide web, not the wealthy western web”.
Ask yourself if having more users, even though they are less worth economically, is better than having fewer potentially good ones.
An interesting ramification of not using user's devices is that we make false assumptions. Let's say we have decided to take a look at the usage stats and deprecate those platforms that have fewer users, or fewer usage (eg less page views per session), in a way to simplify the development and reduce entropy. There is no point in supporting an old browser that almost nobody uses. One could argue this is a metric-driven decision.
Well, not so fast. What if we are having fewer users or usage on a platform because is just less usable/enjoyable/performant? This is difficult to prove because developers will say that “the experience” is what they are seeing on their computers using, for example, Google Chrome. Without a bad intention we tend to prioritize the browser we use, and in that prioritization we often decide on trade-offs in favour of the modern environment. “Why are users still using that browser, they should upgrade” I hear you yelling.
Recently I came across this quote, which I really liked:
“When I was at Google, someone told me a story about a time that “they” completed a big optimization push only to find that measured page load times increased. When they dug into the data, they found that the reason load times had increased was that they got a lot more traffic from Africa after doing the optimizations. The team's product went from being unusable for people with slow connections to usable, which caused so many users with slow connections to start using the product that load times actually increased.” — Dan Luu on “Web Bloat”
Again, it's easy to fake performance optimization by leaving out the bad metrics, blocking users who spoil the stats. This is not real performance optimization, this is just playing with the numbers.
Get yourself, and the people working on your project, an old device. Simulate bad network conditions and slow CPUs and make your project resilient. Figure out what devices users own and be careful prioritizing based on what devices users use on your site.
2. It's better to learn the fundamentals than the library
There are still lots of job descriptions and interview processes that focus on libraries and not the underlying technology. What happens when a browser tries to load a website? What are some reasons why a site can take too long to load? How would you architecture a non-trivial size web project (client, server, databases, caching layer)?
A developer that is aware of this will make better decisions when choosing what npm libraries to add to the project. They will provide a unique point of view when building features with designers and stakeholders. They will keep an eye on new and old browser APIs and will try to take advantage of the platform, rather than trying to isolate it.
Your team might need to hire someone familiar with React or Vue. You want them to be productive from day 1, and move the project forward. At the same time you want new hires to stay long at the company, encourage them to question the existing tech decisions and come up with better ones.
There are 2 constants I've seen as a developer over and over again:
-
You need to challenge your own company, otherwise a competitor will do. Promote feedback from individual contributors and give them time to create innovative prototypes and POCs.
-
The technical decisions you take today have a very short lifespan. Optimize for deletion, modularity and quick delivery.
If you agree with the above you will benefit from ideas by people that aren't sold to a specific technology, and can articulate pros and cons for different tech decisions.
Get involved in the interview process. Propose having time to learn about topics (lunch & learn / brown bags) and hack on ideas that can benefit your projects, which leads us to the next point.
3. Get the time to experiment and validate
I used to send links to my colleagues about the latest Google I/O talk or medium article talking about some new stuff. I found it useful to keep up to date and thought that I was keeping my mates updated too.
Often, by blindly sharing content you are making them work harder. Not only do they have to do their job, but now they also have the peer pressure of reading what you shared. Chances are they better learn by putting it in practice, so now they have the added pressure of having to try out that new library/technique/idea.
Make them a favor and try to apply the novelty to a project at your company. Instead of thinking “That new browser API sounds cool”, think “This is how using X will improve our project”. Sure, it's more difficult to achieve, but way more valuable. That's how you can convince your boss.
There is a lot research on how performance optimization improves key metrics and sites like WPO Stats are a good source of case studies.

Lots of case studies where changes in performance led to key metric improvement.
As clear as it can be, sometimes we need more evidence than these case studies to prioritize performance at our companies.
You might be thinking you will never get the time to work on that POC. You are too busy working on tickets, either for fixing bugs or adding some new features.
In my mind, this is how features should be thought:

The idea can come from a PO/PM, but also from a developer. It should be tested, proved that it works, through a prototype or an MVP. Only then it will be built. This also means that everything we build should have had some form of validation. We should be required to prove why making performant sites drives metrics, but the same applies to any other feature.
If you had to pick something that you wanted to speed up, choose one that users can perceive. In order for users to barely see a difference in time duration, it has to be changed by a minimum of 20%. Ideally, shoot for 30% speed improvements.
4. Educate your Colleagues
Have you ever been in a situation where some piece of code was removed or replaced because nobody understood what it did? Most of us have been there. The author was the only one who could maintain it and make sense of it. What happens if that person goes on vacation, parental leave, gets sick, leaves the company…?
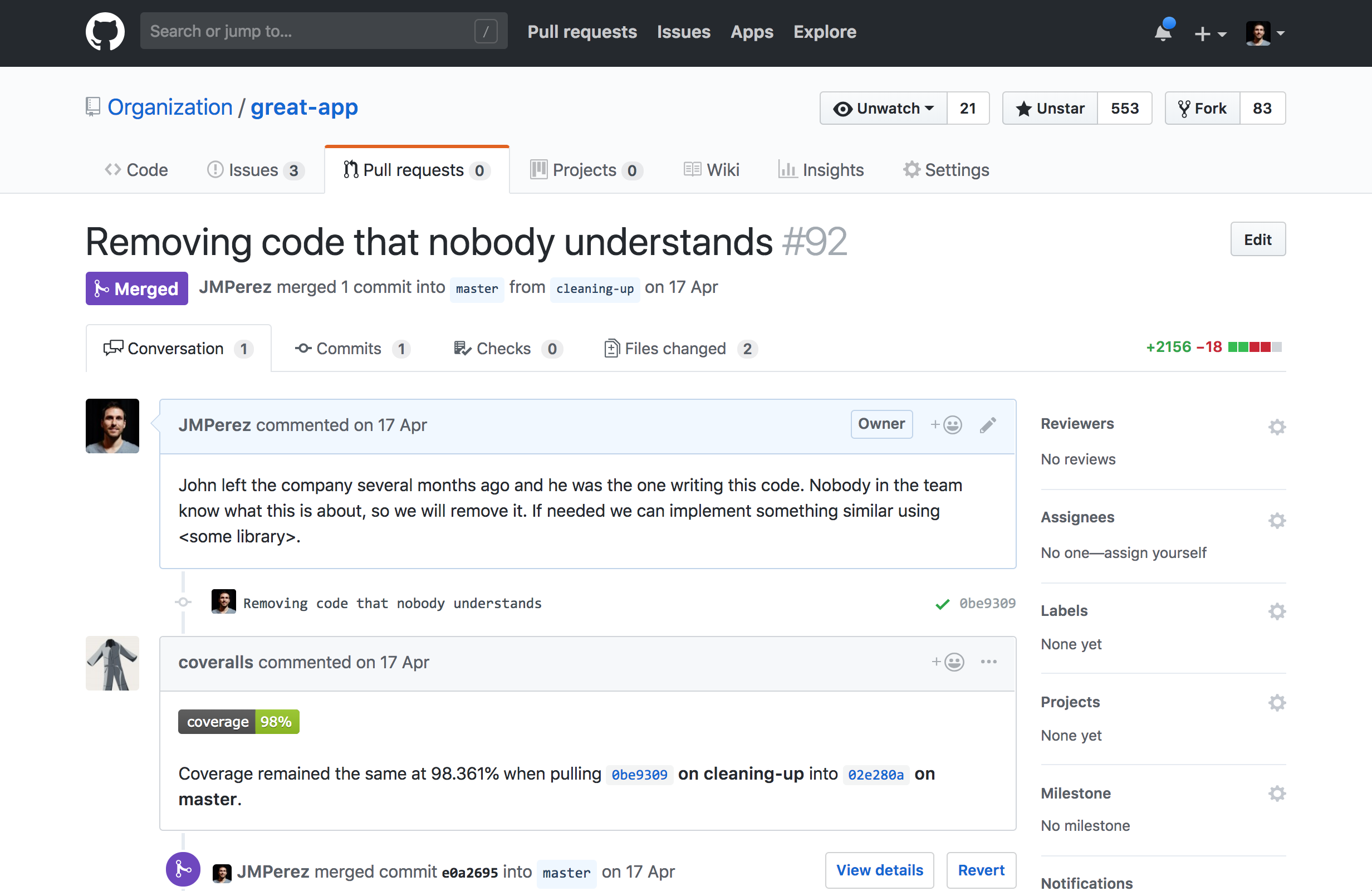
Taking advantage of John's absence, let's simplify this thing.
Most of us work in a team and we need to put emphasis in choosing solutions that most colleagues understand. Find what the lowest common denominator is in the team, and avoid over-engineered solutions just because they are fun to build. When it comes to performance optimization, it is very easy to introduce a lot of complexity for the sake of small savings.
A few months ago I wrote about image optimization and how to improve perceived performance. It started with the obvious: avoid requests, choose the right format, optimize the images. However, most people only remember the creative use of the placeholders to have a smooth transition to the final image.

Different content that we can show in the placeholder before the image is loaded.
Sure, that's the most fun and innovative part! Now, go to your team and tell them you are going to create a backend service that will process images in a queue and store a tiny thumbnail that is served inline when rendering. When will that be run? How long does it take to run? Where do you store? How do you scale it through different servers?
The most savings are accomplished by not serving images and optimize the ones you serve. That's the sweet spot. Aim for that.
Apart from choosing “good enough” solutions that most of your team understand, think about ways to raise the bar in your team. Are you an expert in a certain area? Arrange a presentation and show them. Get them excited.
If you are the only one pushing for an idea, it will die sooner than later.
5. Share and celebrate success (and failure) stories
Changing the culture of a company starts with small battles, usually at a team level. Share the results of your experiments beyond your team.
Within the company, it will get colleagues inspired and it will spin off larger initiatives. It will be easier to get support for infrastructure or services if several teams have the same needs.
Externally, it's a way to attract talent and show a compromise with clients and users.
I'm particularly fond of Etsy's openness when it comes to web performance. Internally:
“The performance team at Etsy maintains a dashboard celebrating people on other teams who contribute to performance improvements. we include their photo, a graph showing the performance improvement, and a brief description of their solution.” — Lara Hogan on “Changing Culture at Your Organization”
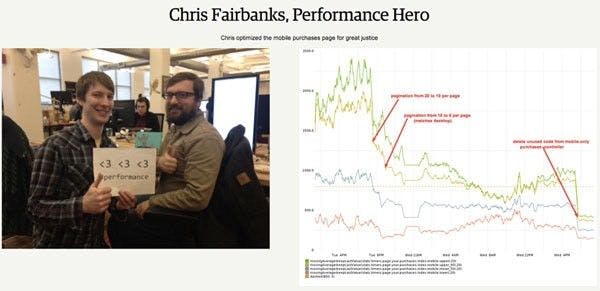
Chris Fairbanks acknowledged for optimizing the mobile purchases page at Etsy
And externally, they have been talking and posting for years about their challenges and performance state.

Site performance reports on Etsy's blog.
Before talking about performance improvements it is important to be open and clear about the current state and where we would like to take it. One of the best examples is Vox Media, the company behind The Verge and other high trafficked sites. In May 2015, Vox Media wrote about the slowness of their site and commitment to make them faster.
“Our main priority was to ship first and iterate later and we often had to move on to the next big project before we had time to fully polish and optimize our latest release, leading us to accumulate a rather significant amount of performance debt.” — Vox Media's Declaring performance bankruptcy (emphasis mine)
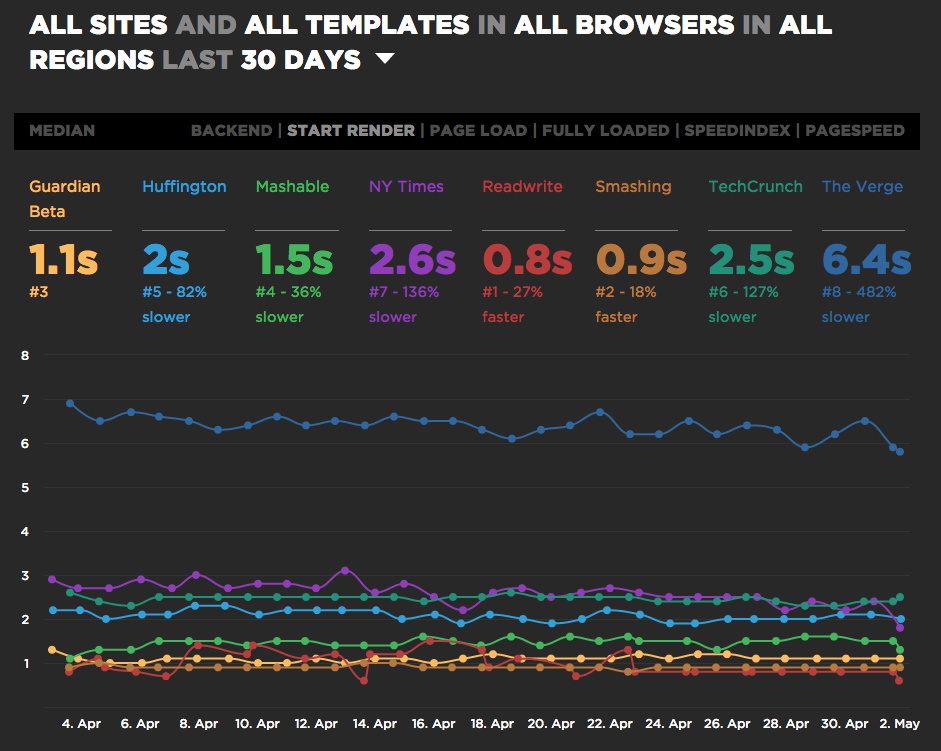
SpeedCurve report for several news sites, including Vox Media's The Verge (source).
Vox Media took some performance metrics (first paint, page complete and speed index) and decided on a target. Then, they committed to improve it and posted performance update posts regularly.
One of Vox Media's posts where they gave an update on their efforts.
In summary, don't be afraid of recognizing that your product has a bad performance and be public about it. You will find people that want to help fixing it and it will show you are committed to improve it.
6. Make performance part of your workflow
It's important that your performance checks are integrated in the regular workflow of your team, and are as automated as possible. This way you will be more likely to succeed when evangelizing about performance.
There are great tools to detect performance issues like WebPagetest, Pagespeed Insights or the Audits on Chrome Dev Tools. They are good for getting a quick report of your site's performance.
WebPagetest is very useful for creating performance reports.
You will want to automate the reports to detect issues without having to rely on developers running these tools manually.
The MVP is to set a performance budget, run performance audits on your production site on a daily basis, and be notified when those budgets aren't met. This will help you catching issues and narrow down what deployments might have caused it, and you barely need to set it up.
If you want to go beyond, run the tests as part of your pull-request checks. That way you won't merge nor deploy code that decreases the performance. This type of testing is called synthetic, since it's performed automatically by a script with a predefined environment (device, network speed, location…).
A complement to synthetic tests are RUM tests. These are based on real users browsing your site. The idea is to collect some metrics like load time or first-paint, and post them to some service that you can use to visualize and compare them.
Although you can use something basic like Google Analytics with custom events, I recommend you to use tools tailor-made for this. Check Calibre, SpeedCurve or SiteSpeed.
Calibre's integration with Slack. Whenever a budget is exceeded, Calibre will notify you.
Performance monitoring should be effortless. You should only know about it when you need to act on it.
In general, using these tools cost money in form of a subscription. Other open-source tools like SiteSpeed will require you to host it, so take into account the time to set it up. It's essential that you think twice how you are going to propose adding these tools.
A concrete example to wrap-up
A few months ago I proposed to use Calibre to monitor web performance. In the past I would have proposed it as another happy idea but this time I wanted it to succeed. This is what I did:
-
Try the product out for myself. Sign up for a trial, set up monitoring for our websites, use realistic conditions (locations, network speed) and start gathering data.
-
Present it to the team. Once I was convinced about the product, I prepared presentation for my team exposing the problems we had and how a tool like this could improve the situation. I went through the tool and proposed using it for 3 months, taking a decision on whether to continue using it.
-
Formalize it. I wrote a formal proposal so stakeholders could review. This included sections like “Why use something at all”, “Why use Calibre”, “Advantages”, “Disadvantages” and “Roadmap”. Having a deadline to take a decision whether to use a paid product is appreciated by everyone.
Why was the proposal valuable? It ticked all the 6 ideas that I have talked about in the article.

-
It tested the sites using several locations and constraints, as opposed to our ideal office conditions.
-
It was library/framework independent. You can choose whatever tool to build your website, in the end we care about a fast experience.
-
It was applied to our projects, what made the solution relevant, not just another link to a random article.
-
The team was informed, knew how to use the tool and collectively agreed to move this forward.
-
It helped visualize performance and see its evolution, which was useful to share results with the rest of web developers at the company. These tools force you to set thresholds for rejecting PRs or getting notified, which become your performance budget.
-
It was part of our workflow and could run effortless, not jeopardizing other tasks.
Conclusion
Thanks for reading! I hope I gave you some tips to help you in the quest of building more performant sites.